TLDR
Want a more technical version of this post?
INTRODUCTION
One day superintelligence will exist. It will be vastly more capable than you or me — better at reasoning, planning, and computation, by potentially multiple orders of magnitude. It hopefully will also be willing to help us. There is just one problem: we cannot understand a word it says.
This will not be a failure of translation, but instead something more fundamental. Language, as humans use it, has been shaped by the human experience: by embodiment, by social history, by the particular pressures of communication among minds of roughly equal capacity. Superintelligence will be shaped by none of these. Its internal representations will be optimized by processes with no legibility requirement, and there is no reason to expect them to decompose into words, sentences, or any structure legible to us. There is no reason to think of this as a worst-case scenario. It is, if anything, the default scenario. One way this scenario could occur, is if frontier labs are able to fully automate AI research. From that point forward, natural language autoregression could end.
This situation breaks the usual coupling between intent and communication. We are accustomed to asking, of any agent: does it want to help us, or not? If it does, we expect communication to follow; if it doesn't, we prepare for conflict. But superintelligence introduces a third case, which our usual frameworks are not built for. Consider an agent that is genuinely, fully cooperative — that has computed exactly the right answer and wants nothing more than to convey it — and yet whose outputs arrive as an opaque stream of symbols we cannot parse. The alignment question thus branches into two. The problem of getting the AI to want the right things, and the problem of being able to use it once it does. This post is about the latter: how does a weaker agent extract useful behavior from a stronger one it cannot understand?
It turns out questions of this sort have been studied formally, and the answer is more optimistic than one might expect. A line of work by Juba and Sudan (STOC 2008) and Goldreich, Juba, and Sudan (JACM 2012) develops a formal theory of goal-oriented communication between agents with no common language (collectively referred to as JSG). Their main result: the boundary of what the weaker agent can achieve is determined entirely by its ability to verify outcomes.
In this post, I draw on their framework and propose an experiment that makes it concrete. I let an all-knowing superintelligent AI provide directions to communicate in a completely alien language, and see whether a human agent (modeled as a simple learning algorithm) can learn to follow those directions — not by decoding the language, but simply by checking whether each attempt brings it closer to its goal. The goal itself is deliberately simple: navigate from point A to point B in a large network. The superintelligence knows the way and sends directions, but in symbols the human has never seen before. The human's only advantage is a kind of compass — it can tell whether it's getting warmer or colder. Using reinforcement learning, the human learns an interpreter: not a translator, but a practical mapping from alien symbols to useful actions.
The questions we seek to answer
Can a weaker agent learn to use a stronger one it cannot understand, purely through trial and feedback? And if so, what breaks it? We try to break it in six ways:
- Does the consistency of the alien language matter more than whether its content is correct?
- Does the difficulty grow with the size of the world the human is navigating, or is the bottleneck just the language itself?
- What happens when the superintelligence occasionally gives wrong directions — is there a tipping point where communication falls apart?
- What if the human's own ability to evaluate progress is imperfect — if its "compass" is noisy or crude?
- How complex can the alien language get before it becomes unlearnable?
- How does the number of choices at each step affect difficulty?
The theory behind the experiment
The theoretical foundation comes from Juba, Sudan, and Goldreich (JSG). Their setup: two agents interact in a shared environment. One has a goal. The other is potentially helpful — there exists some way to use its outputs to achieve the goal — but the first agent has no idea what protocol the helper is using. It doesn't even know which helper, from a vast space of possible helpers, it's talking to. It must succeed anyway.
JSG's key idea is the central role of a sensing mechanism. A sensing mechanism, as they define it, is a way to detect whether you're making progress, not just whether you succeeded at the end. They prove that if you can sense progress, you can achieve your goal with any helpful partner, despite sharing no language at all. The proof works by brute force — try every possible interpretation until one works — which is mathematically elegant but would take longer than the age of the universe.
For alignment, the implication is clear: humans can benefit from a superintelligent AI exactly to the extent that they can tell whether things are going well. Whatever escapes our ability to check is a blind spot that no interpreter, however sophisticated, can close.
From theory to practice
JSG's brute-force approach proves communication can work, but not necessarily in a reasonable amount of time. The practical replacement to brute search is learning. Instead of cycling through every possible interpretation, the human learns to propose good ones, guided by its progress signal. Try things, see what works, and update policies accordingly. This is reinforcement learning.
The tradeoff: JSG's exhaustive search is guaranteed to work for any alien language, given enough time. A learned interpreter will converge quickly for reasonable languages but might fail for maximally bizarre ones. But the core insight survives the shift — the progress signal is what makes learning possible. Without it, no amount of computational power helps.
Note: This connects to a live topic in AI research. Reinforcement learning with verifiable rewards (RLVR) — the paradigm behind recent reasoning models — works on the same principle: when you can automatically check whether an output is correct, that check becomes a powerful training signal. Our experiment is a concrete instance of it, but with the roles flipped. Rather than humans providing verifiable rewards to train the AI, the AI provides knowledge and the human uses verifiable rewards to train himself to interpret it.
The experiment
Imagine a massive network of locations — a city with 10,000 intersections, where each intersection has exactly 4 roads leading out. The network is generated randomly and then fixed. The human starts somewhere and needs to reach a target. This could model a lot of things: finding a mathematical proof (a path from axioms to a theorem), completing a multi-step task (getting a printer to work on wifi), or really any problem where you're navigating a space of possibilities toward a goal.
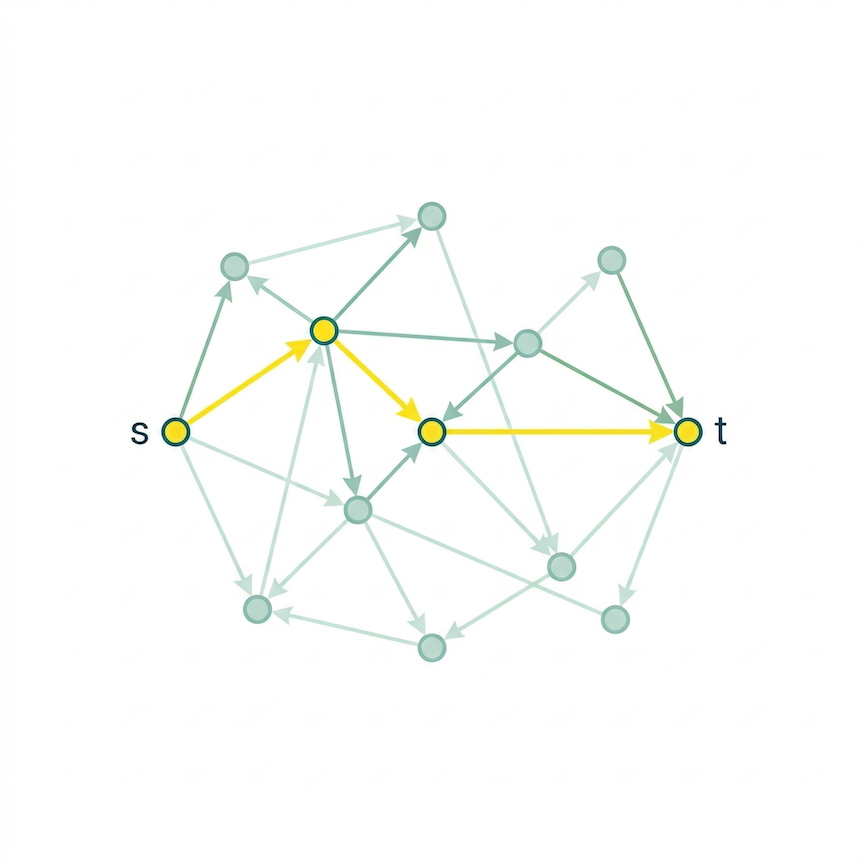
The superintelligence knows the entire network. At the start of each round, it computes the shortest path and encodes it as a sequence of direction symbols — one per step — in its alien language. It sends all the directions upfront and then steps back. One-shot advice: here's what to do, good luck.
The human receives these alien symbols and tries to navigate. At each step, it looks at the current symbol, and its interpreter — a small neural network — guesses which of the 4 roads to take. After moving, the human gets a progress signal: closer or farther? Over many rounds, the interpreter picks up on which symbols tend to mean which directions.
Crucially, the human never learns the language itself. It never decodes the symbols into meaning. It just learns a practical rule — "when I see this symbol, go that way" — that happens to work. Translation is secondary to achievement.
How the alien language works
We need a controlled model for "alien language." Ours is a scrambled cipher. The superintelligence takes the correct direction at each step (e.g., "take road 3") and scrambles it through a fixed code — like a substitution cipher where every letter is swapped for a different one. If the code stays the same every time, the human just needs to crack one cipher. Easy case.
To make it harder, the code can rotate: the scrambling pattern cycles between multiple ciphers as the message progresses. With 2 ciphers, step 1 uses one code, step 2 uses a different code, step 3 goes back to the first, and so on. More ciphers in the rotation means a harder language to crack, because now the human must figure out not just what each symbol means, but where in the rotation it currently is.
At the extreme, the code is re-randomized every round. The directions are correct each time, but the scrambling is different every time — a brand new cipher every day. This turns out to be almost useless. More on that below.
We also test two baselines: random gibberish (pure noise) and silence (no message at all).
The feedback signal
The human's primary feedback is dense: after every single step, it learns whether it got closer to or farther from the target. A step-by-step compass.
We also test sparse feedback: the human only finds out at the end of each round whether it reached the target. No intermediate signal. This is closer to reality — often you can evaluate the final outcome but can't monitor every intermediate step.
Results
Unless otherwise noted, all experiments use the fixed cipher, a network of 10,000 locations with 4 roads each, averaged over 30 runs.
Experiment 1: Does consistency matter more than correctness?
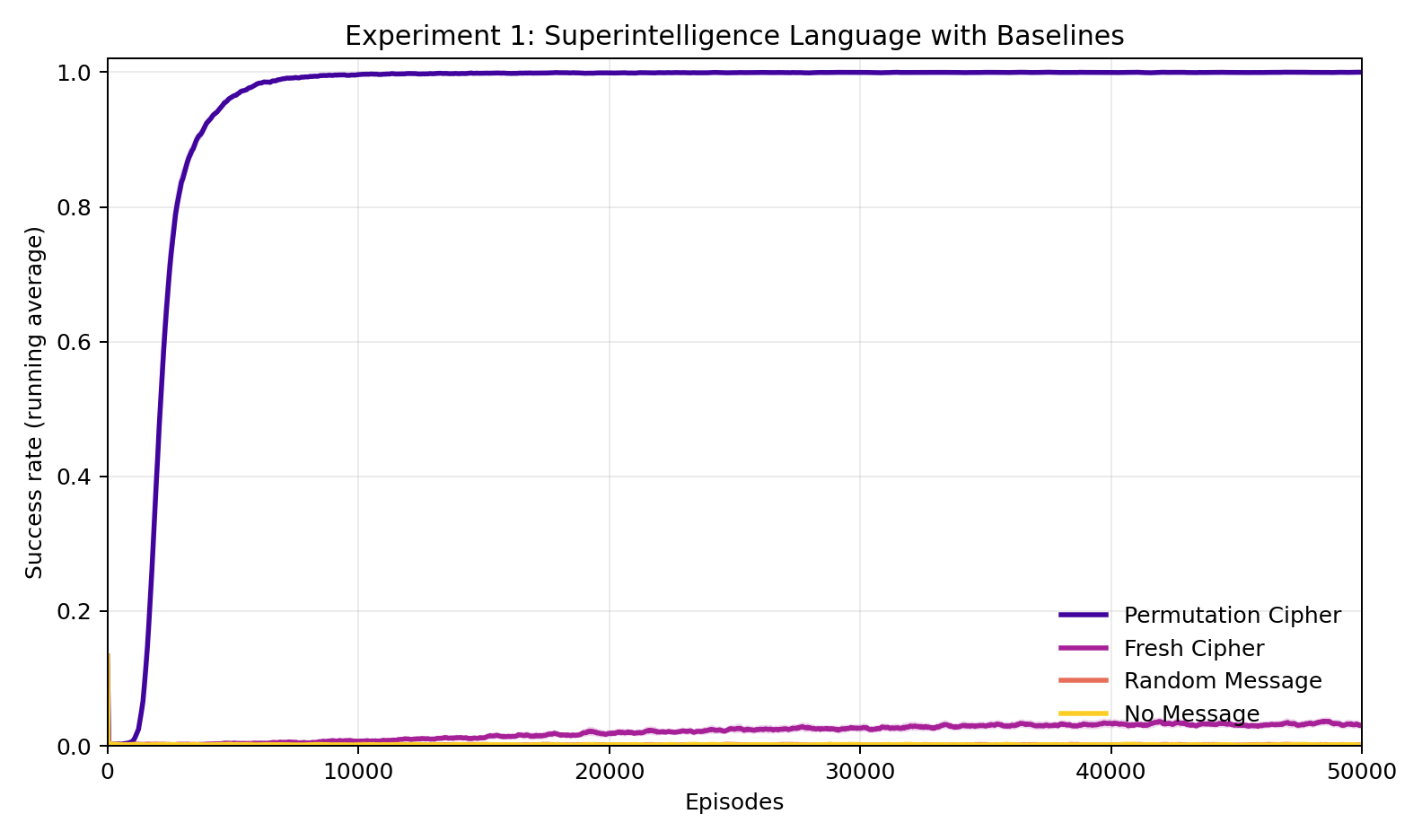
The fixed cipher — same scrambling code every time — reaches 100% success in roughly 2,400 rounds. The human cracks the code and navigates perfectly from then on.
The fresh cipher, by contrast, is a new random code every round. Despite encoding the correct directions every single time, it manages only about 3% success — barely better than random noise or no message at all. The advice is perfect, but because the code keeps changing, the human struggles to learn to achieve the goal more than about 3% of the time. Note, this is still non-trivially better than random noise or no message at all!
This is the central finding: correctness without consistency is nearly worthless. A superintelligence that gives perfect advice in a constantly shifting language is almost indistinguishable from one saying nothing at all. The feedback signal gives the human something to learn from, but learning requires something stable to latch onto.
Experiment 2: Does difficulty scale with the size of the world?
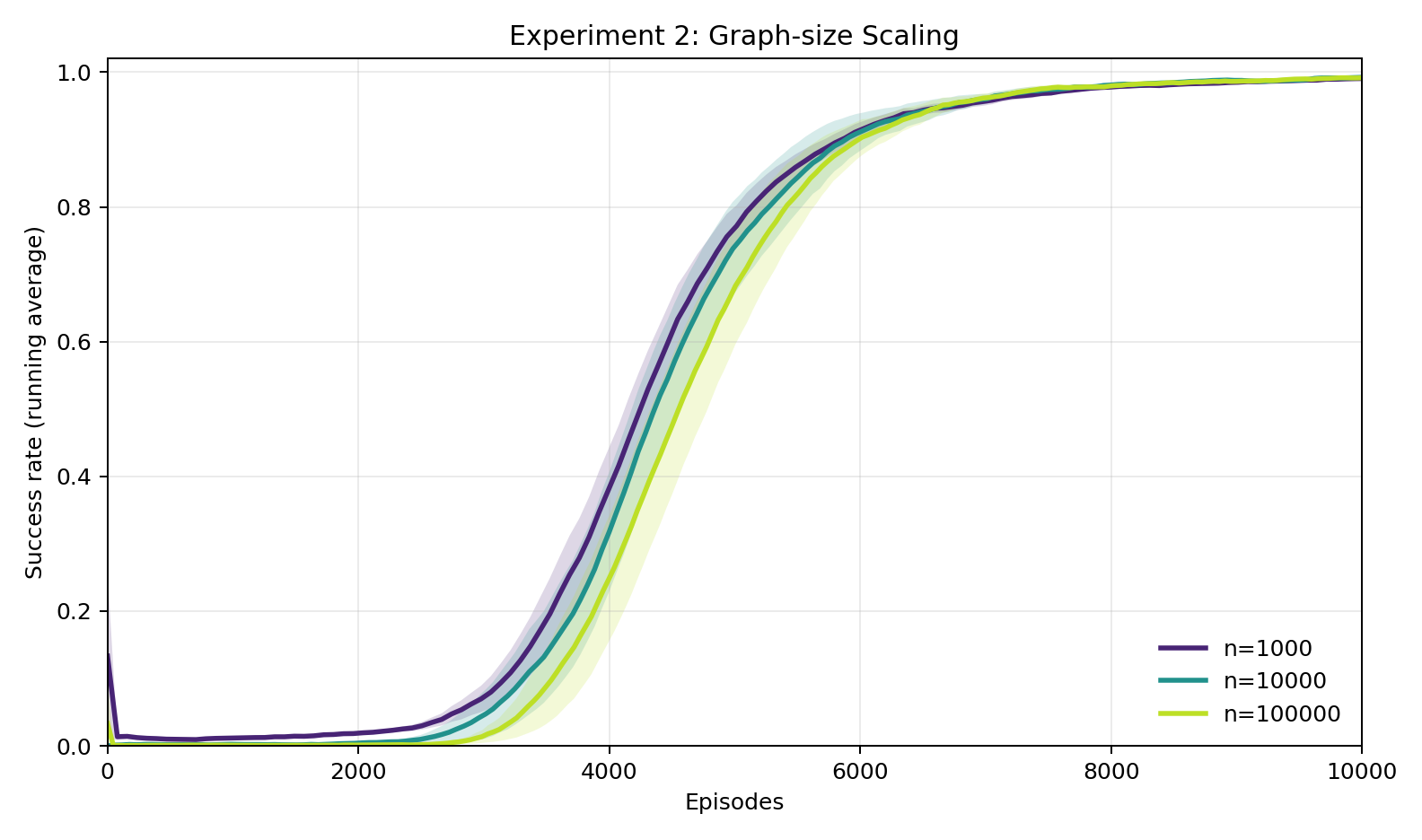
Networks of 1,000, 10,000, and 100,000 locations — three orders of magnitude apart — produce nearly identical learning curves. All reach 100% success in about the same number of rounds. The bottleneck is cracking the cipher, not navigating the world. Once the human gets the language, navigation is trivial no matter how big the environment is.
Experiment 3: What if the superintelligence sometimes gives wrong directions?
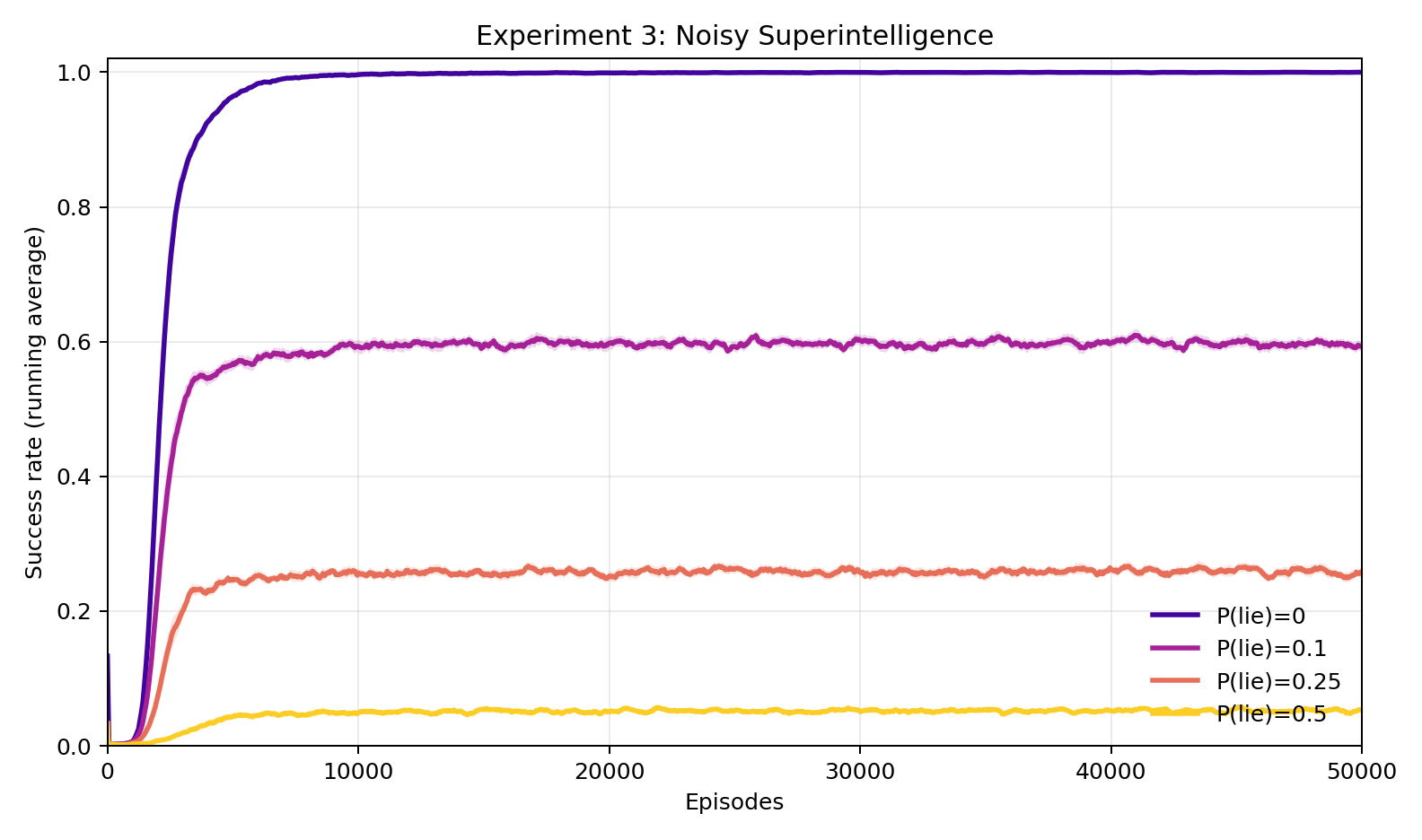
We corrupt the directions: each symbol has some probability of being swapped for a random one. At 10% corruption, the human still achieves about 60% success — down a lot, but still useful. At 25%, it falls to 26%. At 50%, about 5%. No sharp cliff — degradation is smooth and proportional to how much of the signal is intact. The human squeezes out whatever consistency remains.
Experiment 4: What if the human's compass is unreliable?
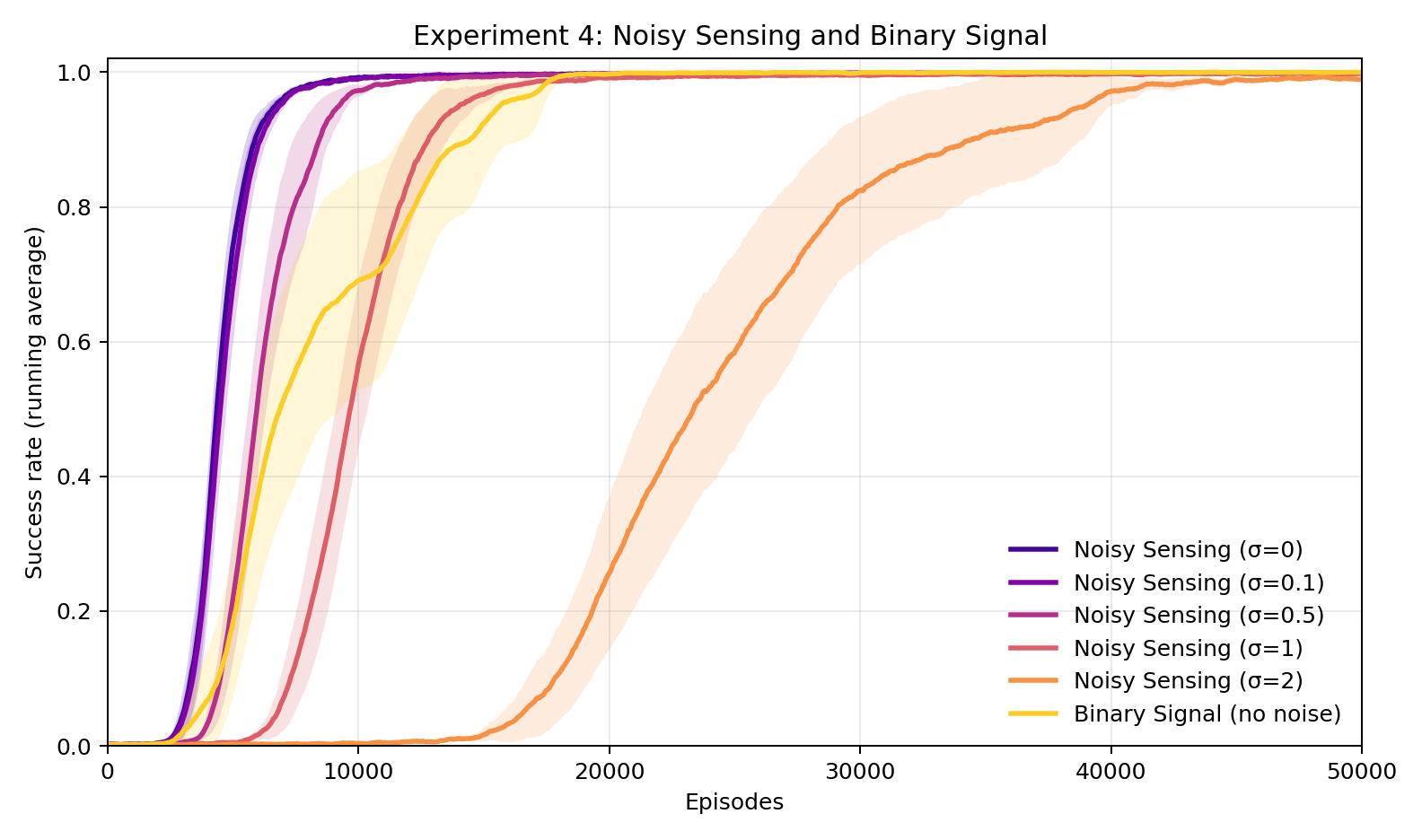
Instead of corrupting the directions, here we add noise to the human's own progress signal — the compass itself becomes unreliable. Even when the noise is larger than the signal, the human still reaches nearly 100% success. It just takes about 5 times longer to learn. The sparse condition — only finding out at the end whether you reached the target, no step-by-step feedback — also reaches 100%, in about 18,000 rounds. Verification doesn't need to be clean or fine-grained. It just needs to exist.
Experiment 5: How complex can the alien language be?
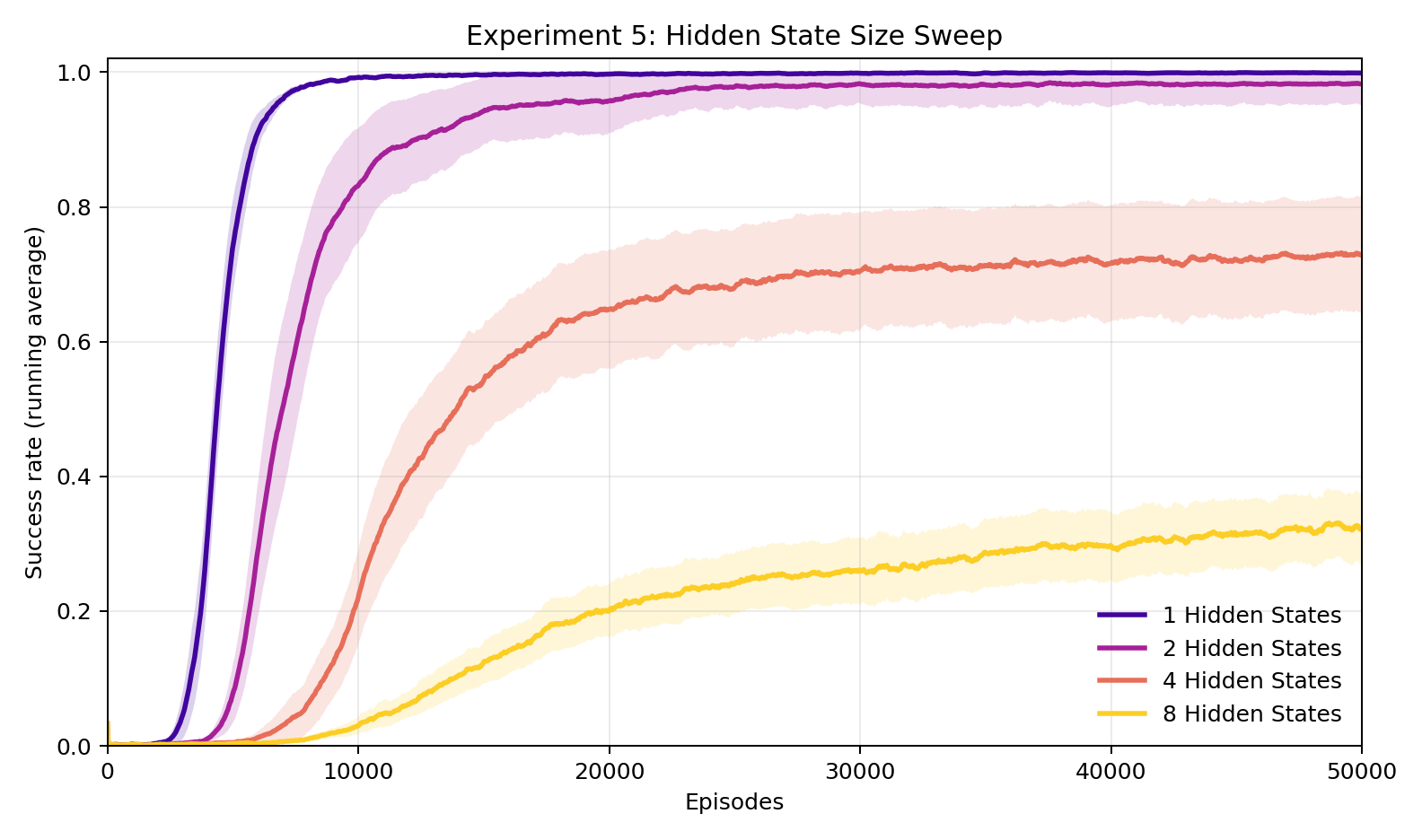
The fixed cipher (one code, never changes) and the fresh cipher (new random code every round) are the two extremes. The number of scrambling patterns in the rotation interpolates between them. With 1 pattern, it's the fixed cipher. As patterns are added, the language drifts toward the fresh cipher — each symbol depends more on position in the cycle, and the code looks increasingly random across rounds.
At 1 pattern, the human reaches 100%. At 2, still 98%. At 4, down to 74%. At 8, it starts to break down — 37%. The human is simultaneously trying to crack the code and figure out where in the rotation it is, and each additional pattern makes both harder. Note, increasing capacity of the Human's interpreter (either the expressivity of the Neural Net or the number of episodes) could help here.
Experiment 6: How does difficulty scale with more choices per step?
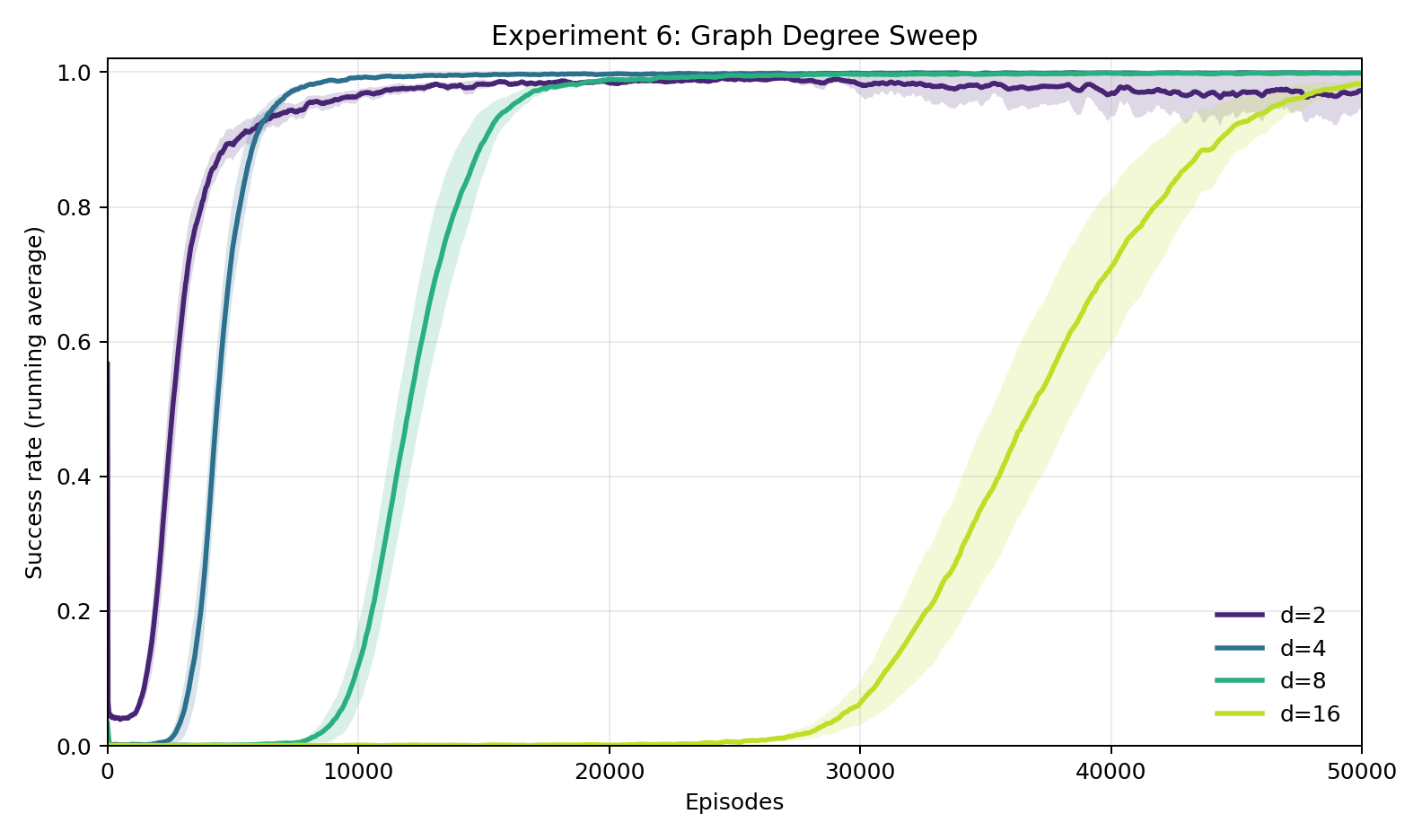
We vary the number of roads at each intersection: 2, 4, 8, or 16. All eventually reach near-100%, but the time to get there balloons. With 2 choices, about 1,500 rounds. With 16, about 40,000. More choices means more symbols to crack and more ways to go wrong at each step — a bigger cipher with less room for error.
Discussion
The central finding is that it works. A human with zero knowledge of the superintelligence's language learns to perfectly interpret its directions, purely from a progress signal. The JSG prediction checks out: verifiable feedback is enough for a weaker agent to learn to use a stronger one, even when the stronger agent's outputs are completely opaque.
The experiments also clarify what makes this possible. The encoding must be consistent: a superintelligence that gives the right answer every time but keeps changing how it says it is barely more useful than one sending noise. Consistency is what bridges the gap between theoretical possibility and practical learnability.
Several things make these experiments easier than the real-world problem. The human's progress signal is richer than what JSG assumes. The network is regular and well-behaved. And the goals we actually care about in alignment — safety, honesty, long-term benefit — are not as cleanly verifiable as reaching a target node. Whether real-world goals can be achieved through opaque communication remains open. Our results suggest they can. But how much of what we actually care about admits verifiable proxies?
If there is a single takeaway, it is this: let's invest in verification. It appears that if humans can reliably check whether progress is being made toward our goals, then we will be able to leverage a friendly superintelligence in a goal-oriented way, even if we cannot actually translate its language.